
By using hypernetworks, researchers can now preemptively fine-tune artificial neural networks, saving some of the time and expense of training.
n
Artificial intelligence is largely a numbers game. When deep neural networks, a form of AI that learns to discern patterns in data, began surpassing traditional algorithms 10 years ago, it was because we finally had enough data and processing power to make full use of them.
Today’s neural networks are even hungrier for data and power. Training them requires carefully tuning the values of millions or even billions of parameters that characterize these networks, representing the strengths of the connections between artificial neurons. The goal is to find nearly ideal values for them, a process known as optimization, but training the networks to reach this point isn’t easy. “Training could take days, weeks or even months,” said Petar Veličković, a staff research scientist at DeepMind in London.
That may soon change. Boris Knyazev of the University of Guelph in Ontario and his colleagues have designed and trained a “hypernetwork” — a kind of overlord of other neural networks — that could speed up the training process. Given a new, untrained deep neural network designed for some task, the hypernetwork predicts the parameters for the new network in fractions of a second, and in theory could make training unnecessary. Because the hypernetwork learns the extremely complex patterns in the designs of deep neural networks, the work may also have deeper theoretical implications.
For now, the hypernetwork performs surprisingly well in certain settings, but there’s still room for it to grow — which is only natural given the magnitude of the problem. If they can solve it, “this will be pretty impactful across the board for machine learning,” said Veličković.
Getting Hyper
Currently, the best methods for training and optimizing deep neural networks are variations of a technique called stochastic gradient descent (SGD). Training involves minimizing the errors the network makes on a given task, such as image recognition. An SGD algorithm churns through lots of labeled data to adjust the network’s parameters and reduce the errors, or loss. Gradient descent is the iterative process of climbing down from high values of the loss function to some minimum value, which represents good enough (or sometimes even the best possible) parameter values.
But this technique only works once you have a network to optimize. To build the initial neural network, typically made up of multiple layers of artificial neurons that lead from an input to an output, engineers must rely on intuitions and rules of thumb. These architectures can vary in terms of the number of layers of neurons, the number of neurons per layer, and so on.
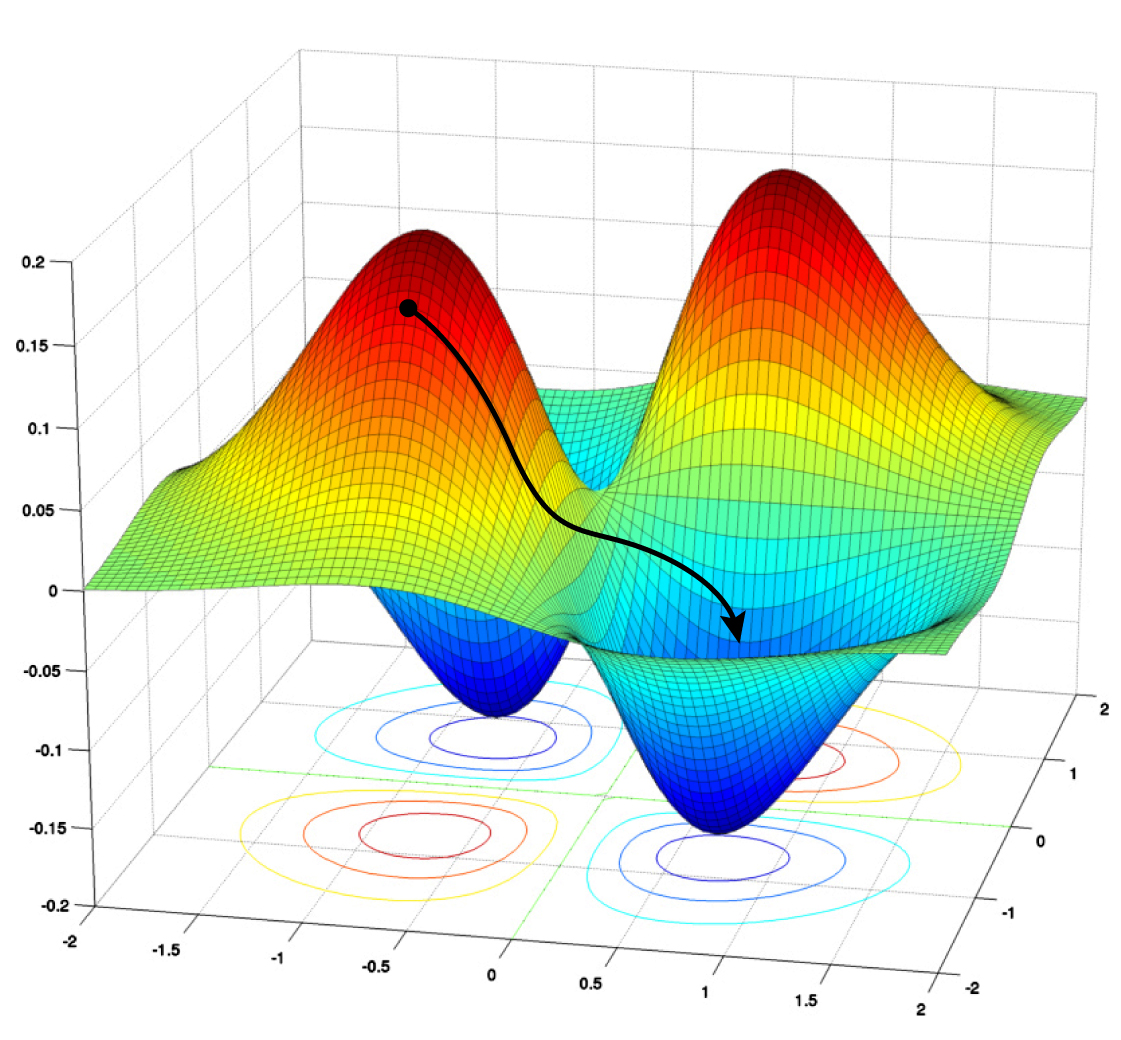
Gradient descent takes a network down its “loss landscape,” where higher values represent greater errors, or loss. The algorithm tries to find the global minimum value to minimize loss.
Samuel Velasco/Quanta Magazine; source: math.stackexchange.com
One can, in theory, start with lots of architectures, then optimize each one and pick the best. “But training [takes] a pretty nontrivial amount of time,” said Mengye Ren, now a visiting researcher at Google Brain. It’d be impossible to train and test every candidate network architecture. “[It doesn’t] scale very well, especially if you consider millions of possible designs.”
So in 2018, Ren, along with his former University of Toronto colleague Chris Zhang and their adviser Raquel Urtasun, tried a different approach. They designed what they called a graph hypernetwork (GHN) to find the best deep neural network architecture to solve some task, given a set of candidate architectures.
The name outlines their approach. “Graph” refers to the idea that the architecture of a deep neural network can be thought of as a mathematical graph — a collection of points, or nodes, connected by lines, or edges. Here the nodes represent computational units (usually, an entire layer of a neural network), and edges represent the way these units are interconnected.
Here’s how it works. A graph hypernetwork starts with any architecture that needs optimizing (let’s call it the candidate). It then does its best to predict the ideal parameters for the candidate. The team then sets the parameters of an actual neural network to the predicted values and tests it on a given task. Ren’s team showed that this method could be used to rank candidate architectures and select the top performer.
When Knyazev and his colleagues came upon the graph hypernetwork idea, they realized they could build upon it. In their new paper, the team shows how to use GHNs not just to find the best architecture from some set of samples, but also to predict the parameters for the best network such that it performs well in an absolute sense. And in situations where the best is not good enough, the network can be trained further using gradient descent.
“It’s a very solid paper. [It] contains a lot more experimentation than what we did,” Ren said of the new work. “They work very hard on pushing up the absolute performance, which is great to see.”
Full article: Researchers Build AI That Builds AI


